 Секционирование (partitions) - один из основных инструментов для обеспечения оптимальной работы с большим объёмом данных за счёт горизонтального масштабирования. Повышается управляемость и производительность, как модификации данных, так и запросы на выборку.
Секционирование (partitions) - один из основных инструментов для обеспечения оптимальной работы с большим объёмом данных за счёт горизонтального масштабирования. Повышается управляемость и производительность, как модификации данных, так и запросы на выборку.
Кроме того, можно повысить производительность, применяя блокировки на уровне секций, а не всей таблицы. Это может уменьшить количество конфликтов блокировок для таблицы.
Но не все обращают внимание на ещё одну уникальную возможность, которую предоставляет секционирование, а именно: обеспечение высокой доступности данных. Сокращает время восстановления после сбоев.
Для демонстрации создадим тестовую БД:
use master;
go
if db_id( 'TestDB' ) is not null
drop database TestDB;
go
create database TestDB
on ( name = 'TestDB', filename = 'c:\temp\TestDB.mdf' )
log on ( name = 'TestDB_log', filename = 'c:\temp\TestDB.ldf' );
go
Теперь к нашей новой БД добавим несколько файловых групп, каждая из которых будет состоять из одного вторичного файла данных (*.ndf):
alter database TestDB add filegroup FG1;
alter database TestDB add filegroup FG2;
alter database TestDB add filegroup FG3;
alter database TestDB add filegroup FG4;
alter database TestDB add filegroup FG5;
alter database TestDB add filegroup FG6;
alter database TestDB add filegroup FG7;
alter database TestDB add filegroup FG8;
alter database TestDB add filegroup FG9;
alter database TestDB add filegroup FG10;
alter database TestDB add filegroup FG11;
alter database TestDB add filegroup FG12;
go
alter database TestDB
add file ( name = 'fg1', filename = 'c:\temp\fg1.ndf' ) to filegroup FG1;
alter database TestDB
add file ( name = 'fg2', filename = 'c:\temp\fg2.ndf' ) to filegroup FG2;
alter database TestDB
add file ( name = 'fg3', filename = 'c:\temp\fg3.ndf' ) to filegroup FG3;
alter database TestDB
add file ( name = 'fg4', filename = 'c:\temp\fg4.ndf' ) to filegroup FG4;
alter database TestDB
add file ( name = 'fg5', filename = 'c:\temp\fg5.ndf' ) to filegroup FG5;
alter database TestDB
add file ( name = 'fg6', filename = 'c:\temp\fg6.ndf' ) to filegroup FG6;
alter database TestDB
add file ( name = 'fg7', filename = 'c:\temp\fg7.ndf' ) to filegroup FG7;
alter database TestDB
add file ( name = 'fg8', filename = 'c:\temp\fg8.ndf' ) to filegroup FG8;
alter database TestDB
add file ( name = 'fg9', filename = 'c:\temp\fg9.ndf' ) to filegroup FG9;
alter database TestDB
add file ( name = 'fg10', filename = 'c:\temp\fg10.ndf' ) to filegroup FG10;
alter database TestDB
add file ( name = 'fg11', filename = 'c:\temp\fg11.ndf' ) to filegroup FG11;
alter database TestDB
add file ( name = 'fg12', filename = 'c:\temp\fg12.ndf' ) to filegroup FG12;
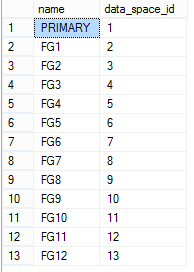
Теперь наша БД состоит из 13 файловых группы: первичной и 12 вторичных
use TestDB;
go
select name, data_space_id from sys.filegroups;
go
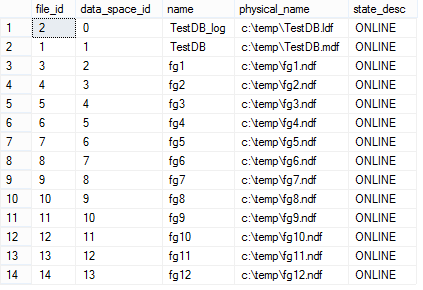
Файлы:
use TestDB;
go
select file_id
, data_space_id
, name
, physical_name
, state_desc
from sys.database_files
order by data_space_id;
go
Все эти подготовки были сделаны не случайно, теперь мы создадим функцию и схему секционирования. При этом мы будем секционировать нашу будущую "важную" таблицу с данными за 2012 год по месяцу. Каждая отдельная секция будет располагаться в своей выделенной файловой группе.
use TestDB;
go
create partition function pf_dt (datetime)
as range right
for values ( '20120101', '20120201', '20120301', '20120401'
, '20120501', '20120601', '20120701', '20120801'
, '20120901', '20121001', '20121101', '20121201'
, '20130101'
);
go
create partition scheme ps_dt
as partition pf_dt
to ( [primary], FG1, FG2, FG3, FG4, FG5, FG6, FG7, FG8, FG9, FG10, FG11, FG12, [primary] );
go
Обратите ваше внимание, что все данные, которые будут с датой < 2012 и > 2012 года расположатся в файловой группе primary.
Ну, а теперь создадим нашу наиважнейшую таблицу, которая будет содержать информацию о продажах за 2012 год. При этом к этим данным выдвигаются очень серьёзные бизнес-требования в плане доступности.
if object_id ( N'dbo.sales', 'U' ) is not null
drop table dbo.sales;
go
create table dbo.sales
( id int identity
, val varchar(255) default ( replicate ( 'A', 255) )
, price money default ( rand() )
, dt datetime
) on ps_dt( dt );
go
insert into dbo.sales ( dt )
values ( '20120101' )
, ( '20120201' )
, ( '20120301' )
, ( '20120401' )
, ( '20120501' )
, ( '20120601' )
, ( '20120701' )
, ( '20120801' )
, ( '20120901' )
, ( '20121001' )
, ( '20121101' )
, ( '20121201' );
go 10000
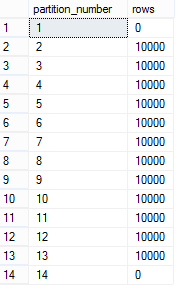
В результате у нас таблица с 14 секциями, 12 из которых содержат данные...в нашем случаи по 10000 строк:
select partition_number, rows
from sys.partitions
where object_id = object_id ( N'dbo.sales', 'U' );
Т.к. у нас каждая секция хранится в отдельной файловой группе, то мы можем создавать резервные копии не только всей БД, но и отдельно для каждой файловой группы.
Следующим скриптом мы создадим 12 резервных копий файловых групп:
backup database TestDB
filegroup = 'FG1' to disk = 'C:\temp\backup\fg1.bak';
backup database TestDB
filegroup = 'FG2' to disk = 'C:\temp\backup\fg2.bak';
backup database TestDB
filegroup = 'FG3' to disk = 'C:\temp\backup\fg3.bak';
backup database TestDB
filegroup = 'FG4' to disk = 'C:\temp\backup\fg4.bak';
backup database TestDB
filegroup = 'FG5' to disk = 'C:\temp\backup\fg5.bak';
backup database TestDB
filegroup = 'FG6' to disk = 'C:\temp\backup\fg6.bak';
backup database TestDB
filegroup = 'FG7' to disk = 'C:\temp\backup\fg7.bak';
backup database TestDB
filegroup = 'FG8' to disk = 'C:\temp\backup\fg8.bak';
backup database TestDB
filegroup = 'FG9' to disk = 'C:\temp\backup\fg9.bak';
backup database TestDB
filegroup = 'FG10' to disk = 'C:\temp\backup\fg10.bak';
backup database TestDB
filegroup = 'FG11' to disk = 'C:\temp\backup\fg11.bak';
backup database TestDB
filegroup = 'FG12' to disk = 'C:\temp\backup\fg12.bak';
Теперь сэмулируем аварию, для этого внесем изменения в одну из файловых групп через любой текстовый редактор. Но прежде необходимо отключить нашу БД (sp_detach_db) или остановить SQL Server, т.к. иначе файлы БД нельзя отредактировать.
use master;
go
exec sp_detach_db 'TestDB';
go
Теперь внесём изменения в один из файлов БД, например в файл C:\temp\fg7.ndf. В качестве редактора я использую Far Manager.
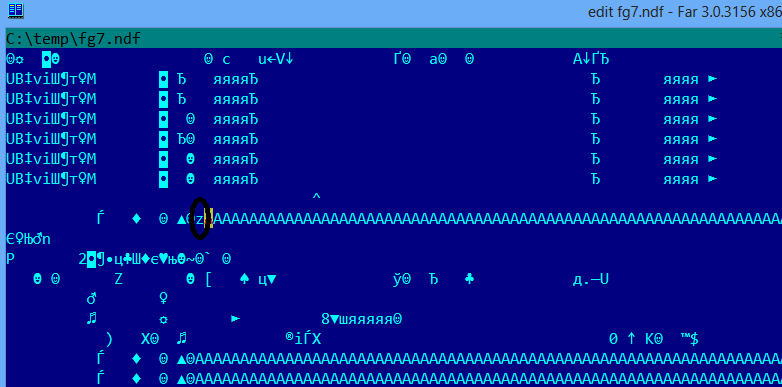
Нам достаточно изменить всего один символ, чтобы наша БД не прошла проверку контрольной суммы. За эту проверку отвечает параметр БД PAGE_VERIFY = CHECKSUM (значение по умолчанию и если вы его не меняли, то вам не стоит о нём беспокоиться), более подробно об этом можно прочитать по ссылке - http://msdn.microsoft.com/ru-ru/library/bb522682.aspx.
Теперь подключим нашу базу:
use master;
go
exec sp_attach_db 'TestDB'
, 'C:\temp\TestDB.mdf'
, 'C:\temp\TestDB.ldf'
, 'C:\temp\fg1.ndf'
, 'C:\temp\fg2.ndf'
, 'C:\temp\fg3.ndf'
, 'C:\temp\fg4.ndf'
, 'C:\temp\fg5.ndf'
, 'C:\temp\fg6.ndf'
, 'C:\temp\fg7.ndf'
, 'C:\temp\fg8.ndf'
, 'C:\temp\fg9.ndf'
, 'C:\temp\fg10.ndf'
, 'C:\temp\fg11.ndf'
, 'C:\temp\fg12.ndf';
go
После подключения БД, попытаемся считать данные из файловой группы, которую мы отредактировали.
select * from dbo.sales
where $partition.pf_dt(dt) = 8;
В результате мы получим ошибку:
SQL Server detected a logical consistency-based I/O error: incorrect checksum (expected: 0x95830087; actual: 0x959e8087). It occurred during a read of page (9:8) in database ID 5 at offset 0x00000000010000 in file 'C:\temp\fg7.ndf'. Additional messages in the SQL Server error log or system event log may provide more detail. This is a severe error condition that threatens database integrity and must be corrected immediately. Complete a full database consistency check (DBCC CHECKDB). This error can be caused by many factors; for more information, see SQL Server Books Online.
При этом данные из других файловых групп доступны для работы
select count(*) from dbo.sales
where $partition.pf_dt(dt) != 8;
--110000
Т.е., не смотря на битые данные в одной из секций, мы продолжаем работать с остальными данными в обычном режиме. Теперь попытаемся восстановить нашу "битую" файловую группу в режиме ONLINE, т.е. без остановки работы с другими данными.
Начинаем всё с переключения нашей ФГ (файловой группы) в режим OFFLINE
alter database TestDB
modify file ( name = FG7, offline );
go
Теперь посмотрим статусы файловых групп:
select file_id
, data_space_id
, name
, physical_name
, state_desc
from sys.database_files
order by data_space_id;
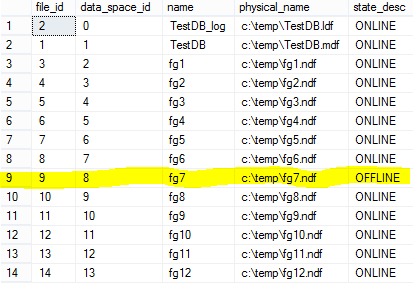
Теперь, при обращении к нашей ФГ, мы получим уже другую ошибку
select count(*) from dbo.sales
where $partition.pf_dt(dt) = 8;
One of the partitions of index '' for table 'dbo.sales'(partition ID 72057594039500800) resides on a filegroup ("FG7") that cannot be accessed because it is offline, restoring, or defunct. This may limit the query result.
Далее выполним само восстановление FG7
use master;
go
restore database TestDB
filegroup = 'FG7'
from disk = 'C:\temp\backup\fg7.bak'
with norecovery;
go
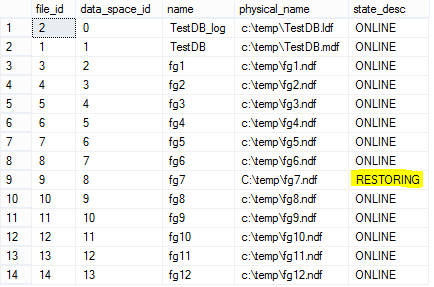
Статус нашей ФГ изменился с OFFLINE на RESTORING.
Последним шагом необходимо сделать копию журнала транзакций и восстановить его с параметром RECOVERY.
backup log TestDB
to disk = 'C:\temp\backup\TestDB_log.bak';
go
restore log TestDB
from disk = 'C:\temp\backup\TestDB_log.bak'
with recovery;
go
После этого статус ФГ сменится на ONLINE и все данные нашей таблицы вновь доступны. Мало того, что на протяжении всего этого времени вся наша БД была в полном доступе для пользователей (за исключением данных в FG7), так мы ещё и восстановление произвели в разы быстрее, чем если бы производили поднятие базы из полной резервной копии. Поэтапное восстановление более подробно описано по ссылке - http://msdn.microsoft.com/ru-ru/library/ms177425.aspx
Но теперь мы проведём более серьёзный тест и удалим одну из файловых групп, но прежде сделаем новую резервную копию нашей файловой группы, которую будем удалять:
backup database TestDB
filegroup = 'FG7' to disk = 'C:\temp\backup\fg7.bak'
with init;
Теперь остановим службу SQL Server, удалим файл C:\temp\fg7.ndf и вновь запустим службу SQL Server.
select name, state_desc from sys.databases
where name = 'TestDB';

Обратимся за подробностями к логу
exec xp_readerrorlog;

И так: наша база данных повреждена т.к. нет доступа к одному из файлов. Первым делом нужно вернуть БД в оперативный доступ. Для этого необходимо перевести в OFFLINE одну ФГ, файл которой "пропал", а всю базу перевести в ONLINE-режим.
alter database TestDB
modify file ( name = FG7, offline );
go
alter database TestDB set online;
go
Далее восстановление очень похоже на то, что мы делали ранее
use master;
go
restore database TestDB
filegroup = 'FG7'
from disk = 'C:\temp\backup\fg7.bak'
with norecovery;
go
backup log TestDB
to disk = 'C:\temp\backup\TestDB_log_new.bak';
go
restore log TestDB
from disk = 'C:\temp\backup\TestDB_log_new.bak'
with recovery;
go
Вот и всё!
 Подписаться
Подписаться